I was surprised to find that I had a slight, subconscious distrust of dropbox. When I found out the app was made by dropbox I briefly reconsidered whether to even try it. I’m glad I did. I owe Peter Crysdale for the beta invite (and for coming on my podcast!)
I’ve been a long-time user of Gmail + Mail.app, which… aren’t the best integrated pair of apps. In fact, I’ve tried a lot of different email setups. Juno, AOL, vanilla POP3 and IMAP with Outlook, Thunderbird, then back to Outlook, then terrible web-based email (squirrel I think) provided with web hosting. Finally ending up with 2 Gmail accounts and iCloud account.
Being able to send email using the appropriate address is important, it’s not super professional to have people emailing my business address and getting a reply from my personal Gmail account. Doing everything through the Gmail web interface is a bit of a non-starter. I’m not going to switch between 2 Gmail accounts all day. It’s a pain, and it means I don’t see new stuff for a lot longer if I forget to check each one. Every time.
I also just don’t like the new Gmail interface. Leaving me with one option: a third-party mail client.
Mail.app served me well for a long time, but it’s never been a great companion to Gmail. The way Gmail does email simply doesn’t fit the IMAP mold very well. That impedance mismatch has been the cause of much unpleasantness. Mail I meant to archive ended up in the trash (and was deleted). Searching my archive has really only ever worked from the Gmail web interface. I’m still not sure what happens when I flag something as spam in Mail.app – does Gmail get the memo, or not?
Don’t get me started about filters and rules - that all has to live on the Gmail server, and I have a set of rules for each Gmail account. And the iCloud account? Well I’ve just stopped giving out that address due to useless search, lack of filters, and having to use an “@icloud.com” address. Luckily I don’t get much email that way.
First-class support for archive/delete/mark-as-spam
Free download for Mac, iPhone, iPad, and Android
Lists that are actually useful
“Snooze”
Now, I haven’t had an empty inbox in years. Those last 2 are a much bigger deal than you’d first think.
Gmail “tags” are weird. Many of them are hidden in the web UI, and using tags as an organizational tool is clunky. So I’ve more or less settled on starring everything important and leaving anything that still requires action in my inbox.
Now I have 5 main lists where I put things I would have starred:
“Photos” (family pictures, etc)
“Tax” (liberally - anything related to finances really)
[Work] - Ok I cheated this last one is actually one additional list for each work project where I put business related email chains I may need to reference in the future.
Now I keep my inbox nearly empty. The [Work] lists are my todo list. Anything I want to spend more time on, but not right now gets “snoozed.”
Snooze works just like your alarm clock. Makes the message go away for a little while, then return to the top of your inbox. How long can be “later” (3 hours), “tonight” (6 pm), tomorrow, this weekend, next week, among other options. Almost all of them are configurable. Snooze is simple. Snooze is great. Snooze is why my inbox is now empty.
I’m was surprised that Mailbox is a Dropbox product. I’m concerned about their motivation; how do they make money on this? They’ve made versions for iPhone, iPad, Mac, and Android, which is an impressive level of dedication. But is automatic dropbox integration for attachments enough to keep this going?
For entrepreneurs aiming to solve humanity’s communication problems, here’s some free advice: give people communication skills, not another way to distribute their half-baked thoughts. We’ve got plenty of ways to send text around the internet. But communication skills – they haven’t improved much since the proliferation of the internet (if at all).
The problem is that it’s not easy to monetize someone else’s communication skills (who will fund you?). Aside, of course, from hiring them to solve some pressing communication problem. But we can’t all work in PR.
It’s easy to see how we got 140 characters. Advertising. But where are our flying cars? You can barely spend 10 minutes reading or talking about startups and technology without a reference to how we still don’t have flying cars.
We wanted flying cars, instead we got 140 characters
I appreciate the sentiment, but the problems we really need to solve to get flying cars are economic ones. Flight uses a lot of energy. Energy is expensive. The real obstacle is the cost of flying cars – we’ve already figured out air travel – it just costs too much to be practical for day-to-day use.
I have a hard time imagining the founders of twitter thinking to themselves, “Let me go work in BP’s research division so we can eventually have flying cars.” But that’s the reality of it. That or find a way to break the laws of physics, but the prospects aren’t looking good for that. There’s a Nobel Prize waiting for you if you succeed on that front though.
“Let’s focus on the hard problems.” Yes, let’s! But let’s also be honest with ourselves: the hard problems we need to solve are in energy, agriculture, and biology. And hey! What do you know‽ We, as a global society, are spending a lot of resources in those areas. The problems are just really hard.
I don’t mean to say everything is fine or that there aren’t other things to improve (as a species, I disdain nationalism), but I think the problem is overstated.
It’s great that SpaceX is trying to get us on Mars, but again, a huge factor in why there isn’t much investment in that area is cost. Before any number of people are going to go off and colonize mars, we need to reduce the cost to a level that is affordable at scale.
Musk understands this well:
Elon states that he wants to make a trip to the Red Planet affordable for an average American Family. Affordable, he later said, is “no more than half a million dollars”.
Because as long as it costs millions (billions?) of dollars – which we could otherwise spend saving lives here on earth – a mission to colonize Mars is going to be unpalatable. Same for those fancy flying machines you’re yearning for.
This post is a bit of a departure from my normal style, but it took me hours of searching to finally nail this down and resolve the issue.
I’m using OS X 10.9.1 on a Mid-2010 MacBook Pro, Safari is version 7.0.1.
Edit: I’ve also experieced this issue now on OS X 10.8.5 on a Mid-2010 iMac, in Safari 6.1 (Pretty much the same version of Safari)
The Problem
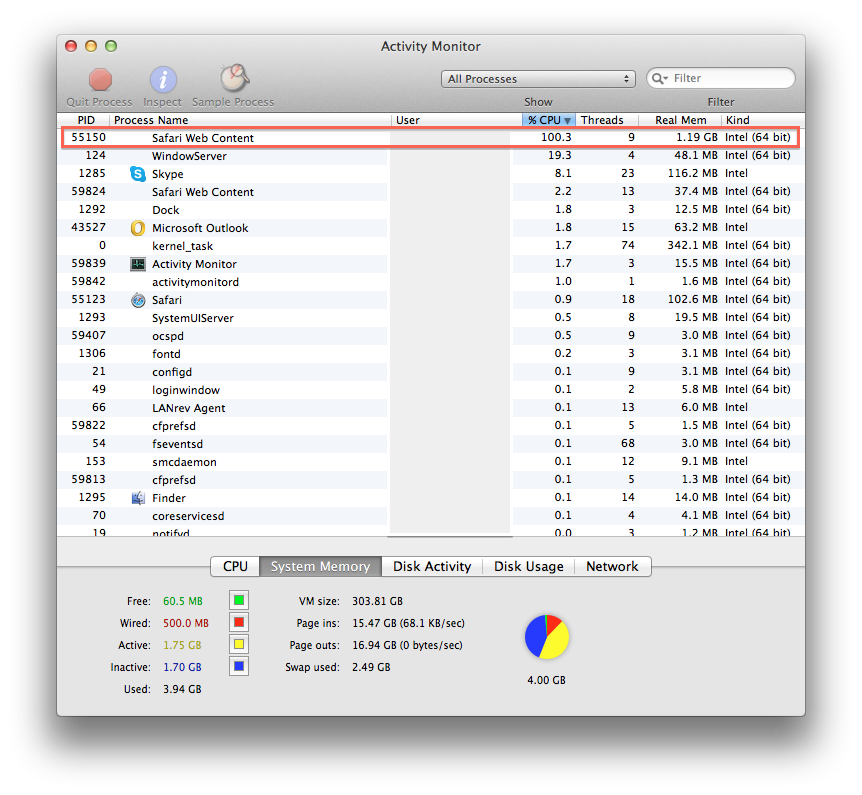
At some point a few days ago I noticed that my CPU fan was blasting for what seemed like no reason at all. So I did what any rational person would do. I opened Activity Monitor.
Safari Web Content was using 100% CPU over 1GB of RAM and was “Not Responding”.
I tried killing the little bugger, but to no avail. Every time I went back to using Safari the problem resurfaced.
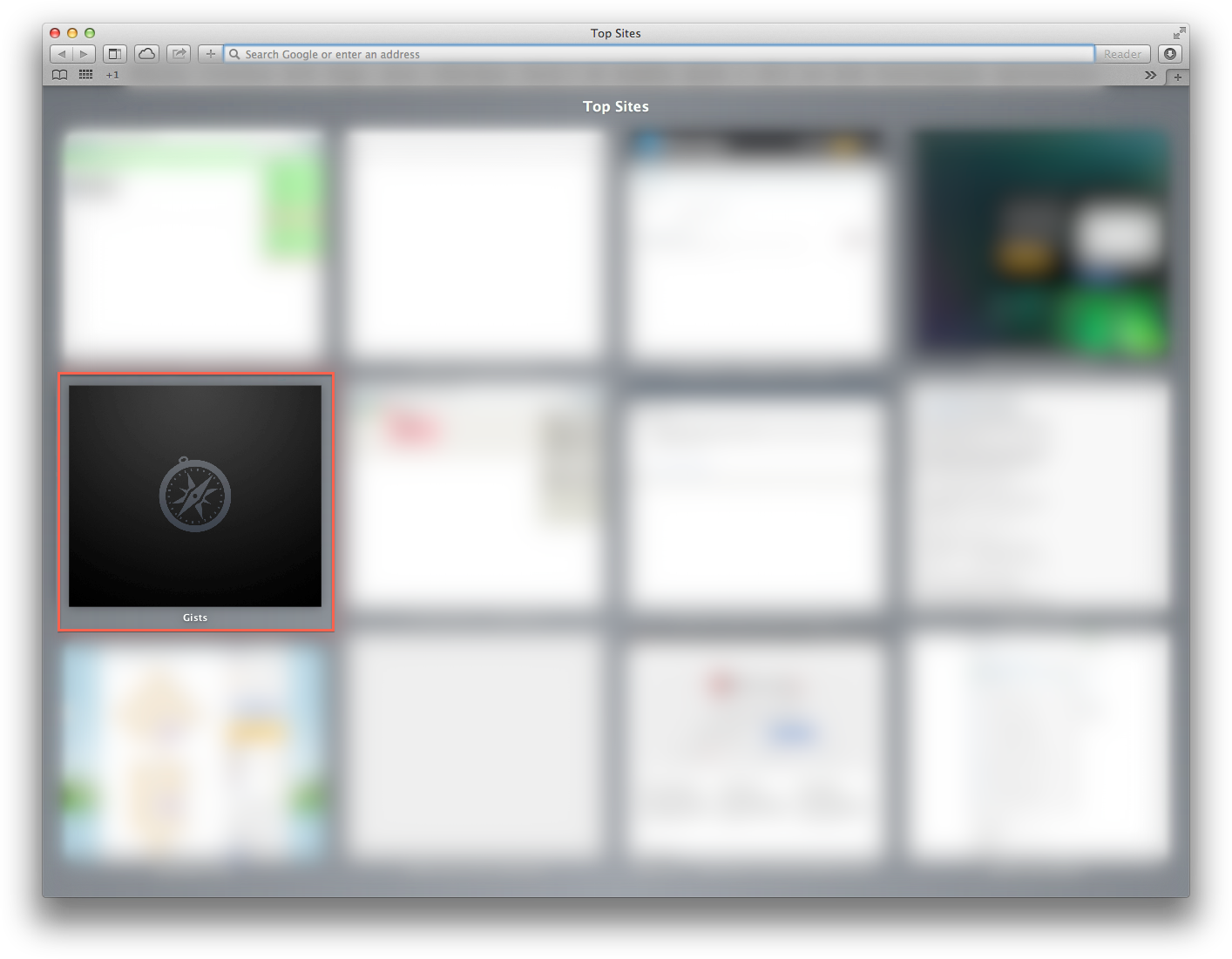
Turns out this is a side effect of things going badly with Top Sites.
Solutions
You can disable Top Sites all together:
Go to “Safari” > “Preferences” > “General” and change new windows and new tabs to open with a blank page (or anything besides Top Sites)
Try to figure out which of your top sites is causing the issue. I suspect that if there is one with no preview (having the black background with a grey safari icon overlaid instead) it is probably the culprit, but I can’t verify that. [update]: I have confirmed this to be the case.
Another theory I have about which sites to remove from Top Sites is ones that use a lot of JavaScript or Flash.
Safari has to run and render all code in the website in order to generate the preview. The more code it has to run, the more potential for problems.
Anyway hope this helps some poor person with this problem :)
edit: I’ve just discovered that if you hover over the “Safari Web Content” item in Activity Monitor, the hover text will show the url of the page being rendered!
edit 2: The trick mentioned in the previous edit is nice, but doesn’t work on the Safari Web Content process that hangs, only the ones spawned for browser tabs. Doh!
I’ve been reading Peter Harrington’s “Machine Learning in Action,” and it’s packed with useful stuff! However, while providing a large number of ML (machine learning) algorithms and sufficient example code to learn how they work, the book is a bit dry.
So I’ve decided to make my contribution to democratizing ML by posting simple explanations of these algorithms.
Why Python?
Pure Python isn’t the most (computationally) efficient way to implement these algorithms, but that isn’t the purpose here. The goal is to help humans understand how these algorithms work. Python is great for that. That’s why the book uses Python as well.
But Harrington takes the alternate route of using the (very powerful) numpy from the get-go, which is more performant, but much less clear, at the expense of the reader.
Well that’s crap; let’s start learning!
What is KNN (K nearest neighbor) good for?
This is a good question to answer up front. Why are we doing this in the first place?
KNN is a “classifier”, which is a type of algorithm that (you guessed it) classifies things.
Let’s put it in more concrete terms: We want to teach the computer to answer the question, “What kind of fruit is this?”
You’re the owner of an orchard, and you’re tired of paying workers to sort your fruits on the assembly line. The job is boring, the workers hate it, and you already measure the weight and color of every fruit on the line anyway. It should be simple enough to have a machine do it.
You have a set of already classified (categorized, tagged, etc) information - and you want to automatically figure out where new data (fruits) fits into your classification automatically. i.e., Is it an Apple or a Banana?
Here’s some fruit the workers logged before they got shit-canned:
Notice they assigned numbers to the colors, that’s useful because we need to do math with these values (numbering non-numerical stuff is known as discretizing). The colors are in order of the color wheel, so similar colors are closer together than less similar colors.
Here’s the color key from the foreman’s clipboard:
red 1
orange 2
yellow 3
green 4
blue 5
purple 6
So our data set has some apples which are red, green, and yellow, and a bunch of bananas which are all yellow except one that is green.
It’s 9 AM.
A loud bell rings.
The conveyor belt starts turning, and fruit starts flowing in from outside.
But the factory is empty. All our factory workers are home learning to maintain fruit classifying robots and re-reading the primitive accumulation of wealth.
…and the first fruit rolls onto the classification machine.
What is this thing?
Weight: 373g
color: 1 (red)
We better write some software to handle that fruit before it rots!
How do we decide whether this unknown fruit is an apple or banana?
The K-nearest-neighbor approach is to calculate the distance between our unknown fruit and each of the known fruits and assume the “k” closest fruits are probably the same type of fruit.
Sort of like graphing all the fruits and drawing a circle around the “?”. Whatever is closest to it is probably the same kind of fruit.
Graph of Fruits
|
|
380 | AA AA
weight | A? A A
330 | A B B
| BB BB
280 |
|__________________________
1 2 3 4 5 6
color
note: the question mark is the “unknown fruit”
Math is delicious
Before we can start with the KNN algorithm, we need to do a little math review. Remember good old pythagorus? a² + b² = c² right? If you’re comfortable with this, just skip to the next section.
If you don’t remember: this is the formula for calculating the hypotenous (see: the diagonal side) of a right triangle.
J
| \
| \
7 | \ ⟵ this side == (5**2 + 7**2) **0.5
| \
-----
5 K
You could also say “longitude” instead of “height”, “latitude” instead of “width” and say you’re calculating the “distance“ from point “J“ to point “K”.
That part is crucial.
Well the real world isn’t 2D, it’d 3D, but I have great news! You can do this in 3D too. So now we can calculate distances in a 3D space the same way:
a**2+b**2+c**2==d**2
or…
d==(a**2+b**2+c**2)**0.5
aside: raising something to the .5 power (i.e., **0.5) is the same as taking the square root.
With KNN you can actually have as many dimensions as you want, but to keep it simple, we’ll just use 2.
OK, back to KNN
So this is what a function would look like that tells us the distance from our unknown fruit to one of the known fruits in our dataset
defdistance(fruit1,fruit2):"""
The args are iterables of the values in the table.
for example the args should look something like this:
# weight, color
fruit1 = [303, 3] # Banana from the data set
fruit2 = [373, 1] # the unclassified fruit
"""# first let's get the distance of each parameter
a=fruit1[0]-fruit2[0]b=fruit1[1]-fruit2[1]# the distance from point A (fruit1) to point B (fruit2)
c=(a**2+b**2)**0.5returnc
Here is the python representations of the stuff we’ve discussed so far:
# the unknown fruit from above
unknown_fruit=[373,1]# This is arbitrarily chosen for this example. Generally
# you need to play with this magic number to find what works
# best for your case.
k=3# here's the dataset as a python list…
dataset=[# weight, color, type
[303,3,"banana"],[370,1,"apple"],[298,3,"banana"],[277,3,"banana"],[377,4,"apple"],[299,3,"banana"],[382,1,"apple"],[374,4,"apple"],[303,4,"banana"],[309,3,"banana"],[359,1,"apple"],[366,1,"apple"],[311,3,"banana"],[302,3,"banana"],[373,4,"apple"],[305,3,"banana"],[371,3,"apple"],]
…and with that being said, let’s sort the dataset using this function…
# using the distance() function from above, sort
# the data set by smallest distances on top
sorted_dataset=sorted(dataset,key=lambdafruit:distance(fruit,unknown_fruit))
Here is the table of distances from our unknown fruit to the known fruits in the data set.
At this point, which classification the unknown fruit belongs to is determined by taking a vote of the “k“ nearest neighbors – so if “k“ is 3, then we take the top 3 fruits by distance and select whichever is most common.
# from the python std library
fromcollectionsimportCounter# take only the first K items
top_k=sorted_dataset[:k]class_counts=Counter(fruitfor(weight,color,fruit)intop_k)# class_counts now looks like this:
# {"apple": 3}
# get the class with the most votes
classification=max(class_counts,key=lambdacls:class_counts[cls])# There you have it!
classification=="apple"
In this case we see that the top 3 are all “Apple“ so we conclude this unknown fruit must be an apple.
You can expand this to more more than two features though. You can actually use that distance formula from earlier with as many dimensions as you want.
Let’s try it with 4:
e==(a**2+b**2+c**2+d**2)**0.5
So if we’d done this using more characteristics of the fruits than just weight and color (like number of seeds in the fruit for instance), the distance calculation (we have 3 factors now) would have just been:
# weight, color, seeds
fruit1=[303,3,1]# Banana from the data set
fruit2=[297,1,4]# unknown (but it's an apple)
a=fruit1[0]-fruit2[0]b=fruit1[1]-fruit2[1]c=fruit1[2]-fruit2[2]distance=(a**2+b**2+c**2)**0.5
You: This is repetitive
True. This code is designed to make it easy to understand… in real life, you should use numpy (or similar) for performance reasons anyway (ML is very computationally expensive).
You: What if one factor is more important than the others?
That’s a really good point. Maybe the number of seeds is much more important than the color of the fruit (it is), but color is still an important differentiator among fruits with the same number of seeds?
Neutralizing the effects of different units
Right now your weight values are much bigger than our color ones, which we’ve discretized to single digit numbers.
That means weight is causing much bigger changes in distance between fruits than color is.
What are we going to do about that?
Well, what if we measure all our inputs on a scale of 0 - 1.0?
That’s Normalization Kyle!
In short, we’re going to take the biggest value in the dataset and the smallest value in the dataset and put all the other numbers on a scale of 0.0 - 1.0 from smallest to biggest.
defnormalize_weight(weight):# convert the units to a float so python's wonky
# division doesn't break anything later on
weight=float(weight)# first subtract 277 (the smallest weight)
# so that the smallest fruit becomes 0.0
x=weight-277# now the biggest fruit is 105 (382-277), but
# we want the biggest fruit to become 1.0 so
# let's divide!
x=x/105returnx
Obviously you wouldn’t hard-code those numbers (largest/smallest weight) in real life. Again, just for clarity.
You can do the same approach with the colors, number of seeds, etc.
If you’re going to normalize your dataset, you have to normalize all the columns. Otherwise you’re not doing what you think you are.
Wait, but I thought we mainly cared about seeds?
Right. So once you’ve done this, let’s say you want number of seeds to be twice as important as weight and color to be half as important as weight.
You’d just multiply the “number of seeds“ value for every fruit in your dataset by 2.0, and multiply the “color“ value of every fruit in your dataset by 0.5. Try calculating the weights now.
These are magic numbers that (like the K value) need to be tested and tweaked to see what will work best for you.
HOMEWORK:
I’m going to leave it as an exercise to the reader to apply these ideas (dataset follows):
Write a distance function that will accept 3 columns of data instead of 2
Normalize the Color, Weight, and # of Seeds columns of the dataset
Apply weights to the columns:
Color is least important: give it a weight of 0.5
Weight is a good differentiator: give it a weight of 1.0
# of Seeds is most important: give it a weight of 2.0
Classify these 3 unknown fruits (UFs) using your classifier
dataset=[# weight, color, # seeds, type
[303,3,1,"banana"],[370,1,2,"apple"],[298,3,1,"banana"],[277,3,1,"banana"],[377,4,2,"apple"],[299,3,1,"banana"],[382,1,2,"apple"],[374,4,6,"apple"],[303,4,1,"banana"],[309,3,1,"banana"],[359,1,2,"apple"],[366,1,4,"apple"],[311,3,1,"banana"],[302,3,1,"banana"],[373,4,4,"apple"],[305,3,1,"banana"],[371,3,6,"apple"],]
After you’ve classified the 3 Unknown Fruits, consider which columns you could remove without losing any accuracy. It’s often the case that simpler classifiers are better, and the facets of your data may not be as related as you originally thought!
This is my first crack at this type of tutorial, so please give me feedback, and/or corrections! (email: blog@jiaaro.com )
I'm sitting on a train, making my 45 minute, 3 mile commute.
And by train, I mean: tiny aluminum can filled to capacity with iPhones and their owners.
The alarming speed and sheer mass of concrete above our heads isn't getting any attention from these nerds.
Because they're too busy looking at iPhones.
But wait a minute – not their own iPhones. A lot of them are looking at somebody else's. In fact, I'd say in a given subway ride at least half of them will glance at their neighbor's display. You know you've done it. Moving, flashing lights are hard to ignore.
Eavesdropping. iVesdropping? Heh. I love a good pun.
Let's talk about pervasive Internet. That idea mobile developers keep spouting about how we have Internet access "everywhere" thanks to our iThings. What shit.
I spend an 90 minutes a day using an iPhone with no Internet. That's very possibly the majority of my phone usage. 5 days a week.
And I'm not the only one.
Most of the iVesdropping I see is people watching somebody else play a game.
I think it's because games are immersive and the device owner is least likely to look up and trigger that awkward moment where you both realize just how long you've been snooping.
Speculations aside, this is not going away. And I know I've searched the App Store on more than one occasion for an app I saw in that sardine can.
Guess which apps I never see down there. Words with friends, song pop, facebook, twitter, buffer.
All those social ones that demand network access.
But Mail works, so does Podcasts, and Reeder, and letterpress (sort of).
And I know that not everyone lives in the city. But cities are cultural centers. Getting big in New York or San-fran can catapult an app into the charts, and the visibility of being in the charts can make or break your sales numbers.
Dear app developers, I'm begging you. Please make your apps work offline. At the very least make sure they don't crash when you launch them without internet (I'm looking at you zynga).